AI server
- IQ4_NL is much slower than Q4_0/1. So maybe quantize kv cache with IQ4_NL is not such a good idea…
- The new generation of mistral models (devstral 2, ministral 3, etc.) seem to have problem with the chat template… https://github.com/anomalyco/opencode/issues/5034
Clawdbot: With gemma 3, I got the “role must alternate between assistant/user” error. With devstral 2, the tool calls are broken. Have to use gemini for now. The local LLM setup was
"models": { "providers": { "local-llm": { "baseUrl": "https://llm.xeno.darksair.org/v1", "apiKey": "sk-intelvsamd", "api": "openai-completions", "models": [ { "id": "default", "name": "Local LLM", "reasoning": false, "input": [ "text" ], "cost": { "input": 0, "output": 0, "cacheRead": 0, "cacheWrite": 0 }, "contextWindow": 32768, "maxTokens": 4096 } ] } } }, "agents": { "defaults": { "workspace": "/opt/clawdbot/clawd", "model": { "primary": "local-llm/default" } } },SillyTavern seems to have a 1-minute timeout for first token generation, even though here the timeout is disabled.
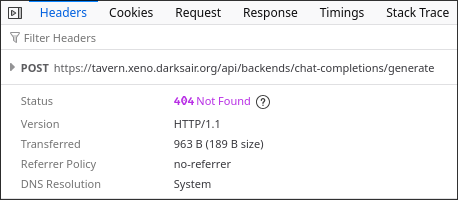
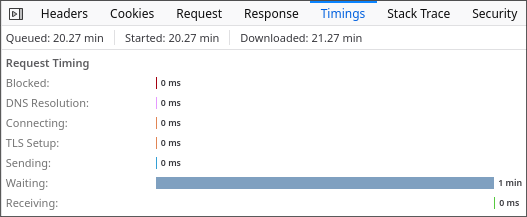
For now I reduced the context limit to 12k.